yuniql is a data platform devops tool using migration-based and database-first delivery model. Migration-based as each changeset to the schema and seed data is a set of carefully prepared scripts controlled with a version number. Database-first as it does not rely on application code to auto-generate the change scripts. yuniql faciliates database devops thru Azure Pipelines and Docker.
At it’s core, yuniql organizes the database migration steps in series of directories and files. Each directory represents an atomic version of your database executed in an all-or-nothing fashion. Utility directories are also created to cover pre and post migration activities. A typical starter project workspace looks like this.
yuniql init
Directory of C:\temp\sqlserver-sample
01/26/2020 09:22 <DIR> .
01/26/2020 09:22 <DIR> ..
11/03/2019 16:58 35 .gitignore
01/26/2020 09:30 67 Dockerfile
01/26/2020 09:22 782 README.md
11/10/2019 10:43 <DIR> v0.00
11/10/2019 10:41 <DIR> _draft
11/10/2019 10:54 <DIR> _erase
11/10/2019 10:42 <DIR> _init
11/10/2019 10:42 <DIR> _post
11/10/2019 10:43 <DIR> _pre
When yuniql run is issued the first time, it inspects the target database and creates required table to track the versions applied. All script files in _init directory and child directories will be executed only this time. The order of execution is as follows _init, _pre, vx.xx, vxx.xx+N, _draft , _post.
yuniql run -a
Executed scripts in _init directory
Executed scripts in _pre directory
Executed scripts in _v0.00 directory
Executed scripts in _draft directory
Executed scripts in _post directory
A successful first-run would have the tracking table filled-up this way.
SELECT * FROM __YuniqlDbVersion;
SequenceId Version AppliedOnUtc AppliedByUser AppliedByTool AppliedByToolVersion
1 v0.00 2020-02-21 06:10 DESKTOP-ULR8GDO\rdagumampan yuniql-cli v1.0.1.0
As you create more versions over time, yuniql discovers all migrations left unapplied from source repository and apply to the target database. Assumming you have two more versions created locally v1.00 and v1.01, the tracking table would have filled this way when yuniql run is issued next time.
Directory of C:\temp\sqlserver-sample
...
11/10/2019 10:43 <DIR> v0.00
11/10/2019 10:50 <DIR> v1.00
11/10/2019 10:50 <DIR> v1.01
...
yuniql run
Executed scripts in _v1.00 directory
Executed scripts in _v1.01 directory
SELECT * FROM __YuniqlDbVersion;
SequenceId Version AppliedOnUtc AppliedByUser AppliedByTool AppliedByToolVersion
1 v0.00 2020-02-21 06:10 DESKTOP-ULR8GDO\rdagumampan yuniql-cli v1.0.1.0
2 v1.00 2020-02-21 06:30 DESKTOP-ULR8GDO\rdagumampan yuniql-cli v1.0.1.0
3 v1.01 2020-02-21 06:30 DESKTOP-ULR8GDO\rdagumampan yuniql-cli v1.0.1.0
When the version is ready for release, you can create deployment pipelines to release the changes to each environment. A typical YAML pipelines in Azure DevOps looks like this.
trigger:
- master
pool:
vmImage: 'windows-latest'
steps:
- task: UseYUNIQLCLI@1
inputs:
version: 'latest'
- task: RunYUNIQLCLI@0
inputs:
version: 'latest'
connectionString: '<your-connection-string>'
workspacePath: '$(Build.SourcesDirectory)\samples\sqlserver-sample'
targetPlatform: 'SqlServer'
additionalArguments: '--debug'
Get started on Sqlserver https://yuniql.io/docs/get-started/. For reference on PostgreSql, MySql and others, https://yuniql.io/docs/get-started-postgresql/
Advanced Options
There are cases when your scripts are conditional to the environment they are executing. You may have scripts that fits in non-production environment but has to be changed when executed in production. To cover this, yuniql discovers environment-aware scripts during migration run. More on this….
A baseline database includes both schema and data. While you can always write scripts to seed your data, it could be easier to bulk load them using CSV files. Yuniql discovers CSV files in the directories and load into tables bearing the name of the file. More on this….
When versioning an existing database, it may help to organize the scripts into collections of sub-directories. Yuniql discovers all directories and child directories, sort them, and execute based on order by name. See more tips and tricks…
Learn further
Credits
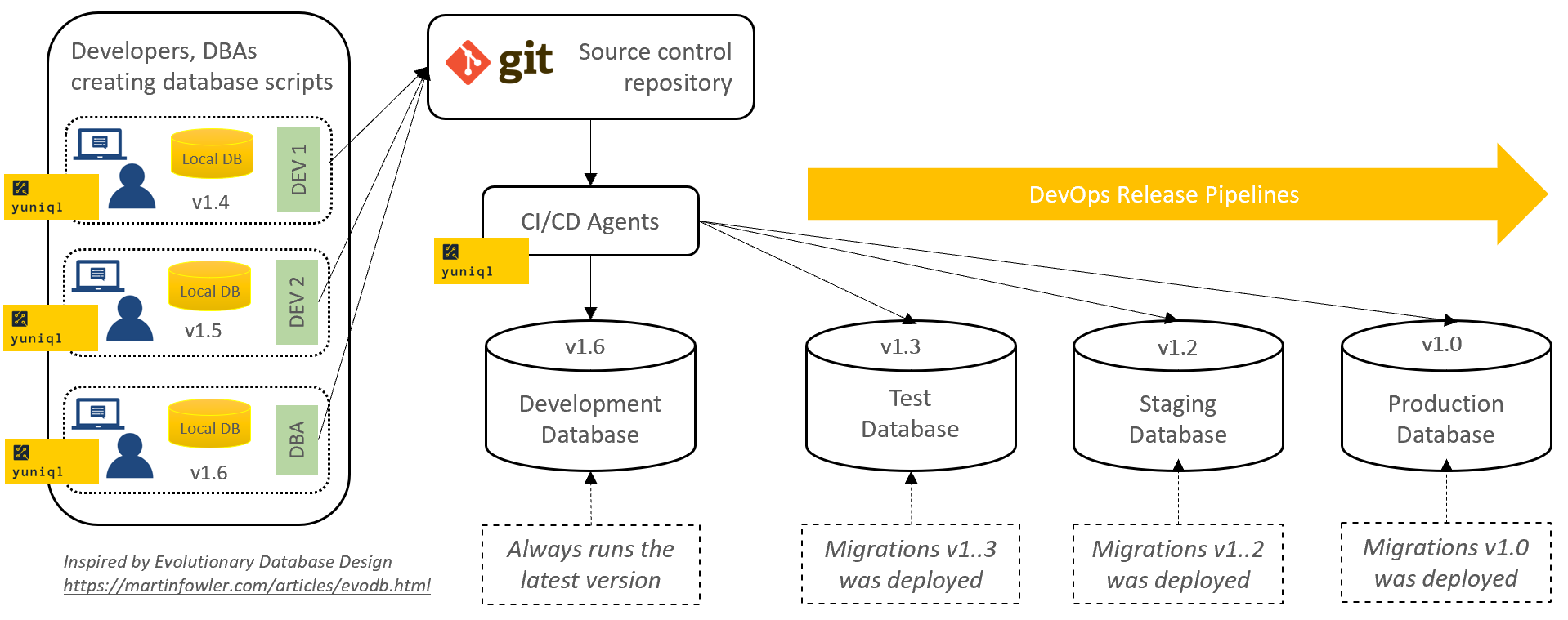
- Original diagram and design inspirations are from Evololutionary Database Design with Martin Fowler and Pramod Sadalage https://www.martinfowler.com/articles/evodb.html
Found bugs?
Help us improve further please create an issue.